gpt-realtime-miniとは?特徴・使い方・料金を徹底解説
.png%3Ffm%3Dwebp%26w%3D1200%26q%3D75&w=3840&q=75)
目次
gpt-realtime-miniとは?
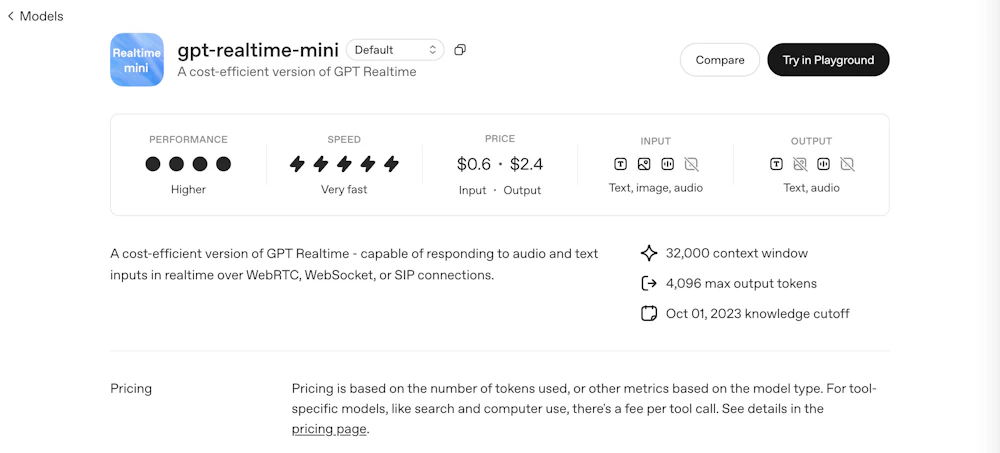
gpt-realtime-mini は、OpenAI が提供する リアルタイム応答型モデル の一種です。
テキストのやり取りだけでなく、ストリーミング形式でのリアルタイム対話(発話中に応答生成を開始できるような体験)を可能にします。
主な特徴は以下のとおりです。
- ストリーミング応答:質問や入力が完了する前でも、応答生成を始められる
- 低遅延設計:対話感覚を妨げない応答速度
- 軽量・効率的:計算リソースを抑えた設計
- 双方向通信サポート(WebSocketなど):通常の REST API ではなく、ストリーミングや双方向通信が可能なインタフェースで動作
このモデルは、「従来のバッチ処理のような応答」ではなく、「会話をリアルタイムで続けられる AI との対話体験」に重きを置いています。
(公式ドキュメントにも “realtime” という命名が示す通り、リアルタイム性を重視したモデルである旨の説明があります) OpenAI Platform
gpt-realtime-mini のユースケース
gpt-realtime-mini の特性を活かせる典型的なユースケース(利用シーン)を以下に示します。
分野 | ユースケース例 | 説明 |
|---|---|---|
音声/会話型AI | 音声アシスタント、チャットボット | ユーザーの発話に即座に反応し、途切れない対話体験を提供 |
ライブ配信・インタラクティブ配信 | 配信者と AI キャラクターの即時応答 | 視聴者と双方向にやり取りする演出、リアルタイム応答で没入感向上 |
教育/語学学習 | 会話練習、発音矯正、インタラクティブ授業 | 学習者の発話や入力に即座にフィードバック |
カスタマーサポート | 接客チャット、音声対応サポート | ユーザーの入力中から対応を準備、応答遅延を削減 |
ゲーム/VR/AR | NPC(ノンプレイヤーキャラクター)のリアルタイム応答 | ユーザー操作に即応し、対話型ゲーム体験を強化 |
これらのユースケースでは、リアルタイム性 が重要な鍵になります。
従来の API 応答(入力 → 応答生成 → 出力)では遅延が目立ちやすく、ユーザー体験を阻害する可能性があります。
gpt-realtime-mini はそのギャップを埋める存在と言えます。
gpt-realtime-mini の使い方
gpt-realtime-mini を活用するには、公式ドキュメントに記載された API の利用が前提です。
以下は一般的な流れと注意点です。
ステップ 1:API キーを準備
OpenAI の開発者ポータルで API キーを取得し、適切な権限を付与します。
ステップ 2:通信形式を理解する
gpt-realtime-mini は、通常の REST API 呼び出しではなく、ストリーミング通信(WebSocket または HTTP/2 のストリーミングなど)を利用して、双方向通信を行います。
これにより、入力がまだ完結していない段階から応答を生成し始めることが可能です。
ステップ 3:モデルを指定して接続
ストリーミング対応エンドポイントに対して、model=gpt-realtime-mini を指定して接続します。
// 例(擬似的な WebSocket 接続例)
const ws = new WebSocket("wss://api.openai.com/v1/realtime", {
headers: { Authorization: `Bearer ${API_KEY}` } <== ステップ1で取得したAPIを設定
});
ws.onopen = () => {
const initMessage = {
model: "gpt-realtime-mini", <== ここでgpt-realtime-miniを選択
// 他のパラメータ(例えば system/user プロンプト等)
};
ws.send(JSON.stringify(initMessage));
};
ws.onmessage = (msg) => {
const data = JSON.parse(msg.data);
console.log("AI からの応答断片:", data.choices[0].delta);
};
上記はあくまで概念例です。実装には認証方式やプロトコル仕様に応じた細かい制御が必要です。
ステップ 4:入力をストリーミング送信
音声入力やユーザーの入力テキストをチャンクごと(断片ごと)に送信することで、AI サイドが入力を受け取りつつ、応答を生成して返してきます。
ステップ 5:応答の受信と表示
受信した応答断片(partial)をリアルタイムに連結・表示して、ユーザーに自然な会話体験を提供します。
gpt-realtime-mini の料金
OpenAI の公式ドキュメント(当該モデルページ)には、gpt-realtime-mini に関する具体的な「料金表(price table)」情報が記載されています。OpenAI Platform
料金(課金モデル)は通常、使用量ベース(分・トークン・秒など)で設定されています。
(※ 正確な単価や詳細な課金単位は、OpenAI 側の発表内容を参照してください)
たとえば、モデル別に「軽量モデル(mini)」と「高精度モデル(large/standard)」があり、軽量モデルの方が低単価で提供される傾向があります。
料金の注意点:
- 通信コスト(ストリーミング通信回数や接続時間)も影響する可能性
- トークン使用量(入力/出力分)にも従って課金
- API 呼び出し以外(ネットワーク転送量など)のコストは別途考慮
まとめ
この記事では、OpenAI の gpt-realtime-mini モデルについて、以下のポイントを解説しました。
- gpt-realtime-mini とは?
リアルタイム応答を可能にするストリーミング対応 AI モデル - ユースケース
音声アシスタント、ライブ配信、教育、ゲーム、カスタマーサポートなど、多様な対話型応用 - 使い方
API キー取得 → ストリーミング接続 → 入力をチャンク送信 → 応答断片を受信して表示 - 料金
使用量ベースでの課金。軽量モデルゆえ比較的低コストな運用が可能(ただし正確な単価は要公式確認)
gpt-realtime-mini は、“即応性” を求める対話型体験の実現を支えるモデルです。
今後、対話型 AI やリアルタイムアプリケーションの中核として、多くのサービスで採用されていくことが予想されます。
※ 本記事の内容は、執筆時点での情報に基づいています。最新の情報と異なる場合がございますので、あらかじめご了承ください。 また、記載されている内容は一般的な情報提供を目的としており、特定の状況に対する専門的なアドバイスではありません。 ご利用にあたっては、必要に応じて専門家にご相談ください。