gpt-image-1-miniとは?特徴・使い方・料金まで徹底解説【OpenAI最新画像生成モデル】
.png%3Ffm%3Dwebp%26w%3D1200%26q%3D75&w=3840&q=75)
目次
gpt-image-1-miniとは?
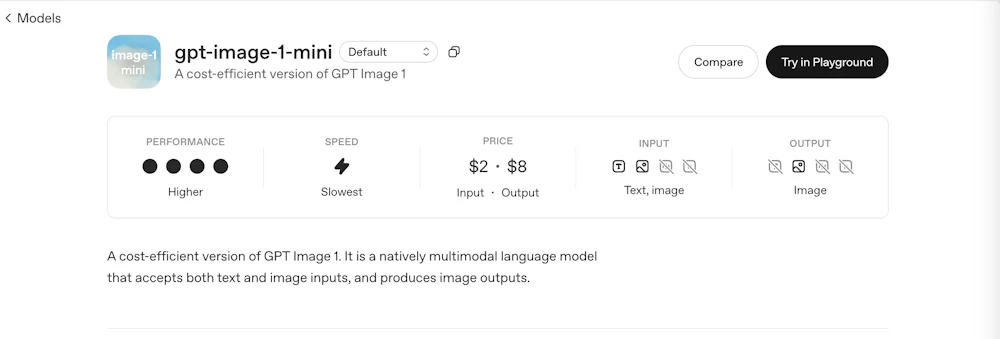
OpenAI DevDay 2025で発表されたgpt-image-1-miniとは、OpenAIが提供する最新の画像生成モデル「gpt-image-1」の軽量版モデルです。
テキストから画像を生成する Text-to-Image機能 や、既存の画像を部分的に修正・加工する Inpainting機能 を備えており、より低コスト・高速で画像生成を行えるのが最大の特徴です。
従来の「gpt-image-1」が高精度な画像生成に特化していたのに対し、gpt-image-1-miniはコスト効率と実用性のバランスを重視したモデルとして設計されています。
そのため、ブログやSNSのアイキャッチ画像、広告バナー、ECサイトの商品画像など、日常的に大量の画像を生成する用途に最適です。
また、gpt-image-1-miniは API経由で利用可能 であり、開発者は自社アプリやWebサービスに組み込むことができます。たとえば、Node.jsやPythonを使って「プロンプトから自動で画像を生成するWebアプリ」や「商品登録時に自動で背景を生成するECシステム」などを簡単に構築できます。
さらに、OpenAIのプラットフォームだけでなく、Azure OpenAI Service や Replicate などでも利用が広がっており、クラウド環境でも柔軟に活用できます。
このことから、gpt-image-1-miniは「高品質な画像生成をより手軽に実現できる次世代モデル」として注目を集めています。
gpt-image-1-miniの利用ケース
gpt-image-1-mini は、コストや処理効率を重視しつつ“実用レベルで使える画像生成・編集”を狙ったモデルのため、以下のような用途で特に効果を発揮します。
主な利用ケース
- コンテンツ制作 / ブログ・SNS用素材生成
記事のアイキャッチ画像、SNS投稿用イラスト、バナー素材など、手早くビジュアルを生成したい場面。
→ フル品質は不要だけれど“それなりに見映えする”画像が求められる場面に適しています。 - Eコマース / カタログ画像補完
商品写真の背景差分生成、スタイル変換、補助的なビジュアル要素の挿入・編集など。
→ 特に大量生成・量産運用でコストを抑えたい場合に有効です。 - マーケティング・広告素材
プロモーションバナー、広告デザイン案、キャンペーンビジュアルなどの試作。
→ アイデアをすばやくビジュアル化し、A/B テストや方向性確認に使える。
gpt-image-1-miniの使い方
以下は gpt-image-1-mini を API 経由で使う典型的な流れおよび注意点です。
利用前準備
- OpenAI API アカウント取得 / モデルアクセス申請
OpenAI の開発者向けアカウントを作成し、モデルアクセス権を得る必要があります。ミニ版は「制限付きアクセスモデル (limited access)」として提供されているとの記述があります。 - API キーの取得 / 認証設定
API キーを取得し、リクエスト時にヘッダー認証などで使用します。 - SDK や HTTP クライアントの選定
OpenAI 提供の公式 SDK(JavaScript / Python など)や、自前 HTTP リクエスト環境を使ってアクセスします。
API 呼び出しの流れ(例:画像生成)
典型的な手順は次のようになります。
- エンドポイント
たとえば/v1/images/generationsのようなエンドポイントを呼び出す(OpenAI の API 仕様に従う)OpenAI Platform+2eesel AI+2 - リクエストボディの指定
プロンプト(テキスト)、出力画像のサイズ(例 1024×1024、1024×1536 など)、品質(low / medium / high)、場合によっては参照画像やマスク情報(編集用途)を含める。 - レスポンス取得
生成された画像データ(URL または Base64)およびメタ情報を取得。 - 画像表示 / 保存 / 後処理
生成された画像をアプリ上で表示したり、保存したり、さらに加工を重ねたりする。
編集用途(Inpainting / 画像編集)
- 編集対象の画像とマスク(どの部分を変更するか)をリクエストに含めることで、部分的な編集を実行できます。
- 参照画像を与えてスタイルを反映するような変換も可能ですが、ミニ版では「input_fidelity」の制御など、一部機能が制限されている可能性があります
実装例(擬似コード:Python)
import openai
openai.api_key = "YOUR_API_KEY"
resp = openai.Image.create(
model="gpt-image-1-mini", <== モデル指定
prompt="a serene forest by moonlight, fantasy style", <== プロンプト指定
size="1024x1024", <== 画像指定
quality="medium" <== 画像クオリティ指定
)
image_url = resp["data"][0]["url"]
print("生成された画像 URL:", image_url)
編集用途では、image や mask フィールドを追加して呼び出します。
注意点・制限
- 使用可能な解像度やアスペクト比に制限がある可能性があるため、仕様ドキュメントを確認すること。
- リクエスト毎のトークン量(テキスト入力、画像入力、画像出力)に応じて課金される。
- レイテンシ(応答速度)を考慮した設計が必要。
- 権利・著作物・安全性フィルタリングなどの利用規約を遵守すること。
gpt-image-1-miniの利用料金
gpt-image-1-mini の料金体系(課金モデル)は「入力トークン (テキスト / 画像)」および「出力トークン (生成画像)」ごとに設定されています。以下は、公開されている情報をもとに整理した内容です。
まとめ
gpt-image-1-mini は、OpenAI が提供する 軽量・低コストな画像生成/編集対応モデル で、次のような特徴と利点があります:
- フルモデルと比較してコスト・リソース効率を重視
- テキスト入力からの画像生成、および編集操作(Inpainting 等)をサポート
- API 形式で提供され、開発環境・サービスに統合しやすい
- 利用料金は入力トークン/出力トークンベースで課金され、一般的な画像モデルよりも安価で使える設計
※ 本記事の内容は、執筆時点での情報に基づいています。最新の情報と異なる場合がございますので、あらかじめご了承ください。 また、記載されている内容は一般的な情報提供を目的としており、特定の状況に対する専門的なアドバイスではありません。 ご利用にあたっては、必要に応じて専門家にご相談ください。